Case Study
OncoVLM: Domain-Specific Foundation Models
Proving that focused training beats raw scale
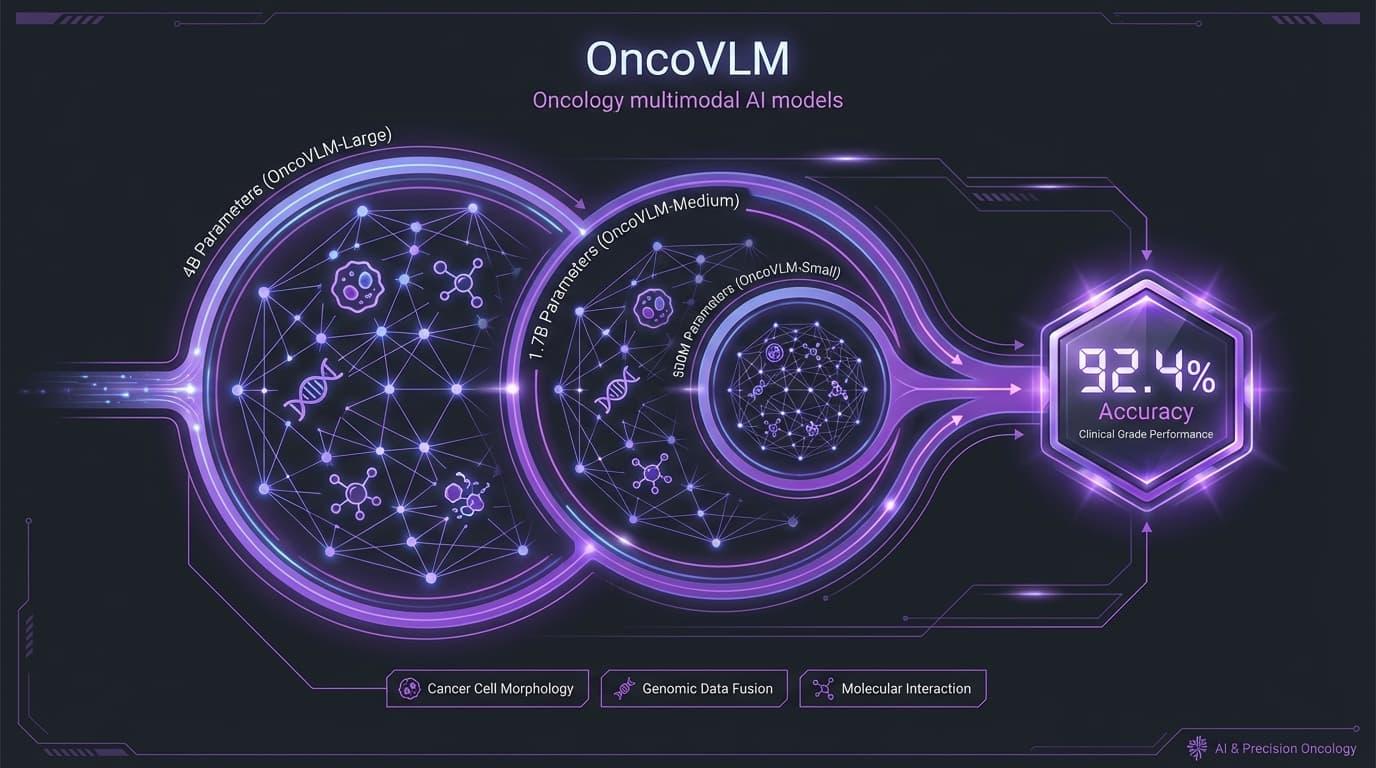
Training oncology-specific multimodal models that outperform larger general-purpose models. Multi-teacher knowledge distillation at three scales: 4B, 1.7B, and 500M parameters.
!The Scale Assumption
The AI field assumed bigger models were always better. But for specialized domains like oncology, general-purpose 70B models often missed domain-specific nuances that smaller, focused models could capture.
- General models lacking oncology-specific knowledge
- Expensive inference costs for large models
- No multimodal understanding of pathology/radiology
- Hallucinations in clinical contexts
Multi-Teacher Distillation
Instead of training one massive model, we distilled knowledge from multiple specialized teachers into smaller, focused students optimized for oncology tasks.
- Three model scales: 4B, 1.7B, 500M parameters
- Multi-teacher distillation from MedGemma, GPT-OSS-20B, Qwen-3-30B
- Multimodal: pathology images, radiology, clinical text
- LoRA fine-tuning for parameter efficiency
Architecture
The training pipeline uses DGX Spark's 128GB VRAM for full-batch training with automated experiment tracking.
Timeline
Key Lessons
10K focused examples can outperform 500K general examples
Multi-teacher distillation captures complementary strengths
Personal GPU infrastructure enables research-grade experiments
Smaller models can beat larger ones on specialized tasks